


またPower Automate Desktop(PAD)関連の記事です。自動化として考えるとそうとう面白くて、まだまだ可能性が広がりそうな感じもしています。
そんな中で、今日、Power Automate DesktopでOCRを使ってみました。
使い方自体はそれほど難しくなかったのですが、そこで感じた初心者が難しいと思うところを少し解説しておきたいと思います。
OCRとは
OCRとは文字を認識するための仕組みです。画像やPDFファイルから入力されている文字を取り出してExcelに入力するといったことができます。もともと画像に123と入力されていてもパソコンはそれを123とは判断できません。ただの画像として認識するのでそのままではExcelのデータとしては使えないのです。形から判断して何の文字か認識できて、文字データに変換するのです。
FAXでのやりとりをやめようというのは、FAXで送られた紙はパソコンに取り込めとしても画像でしか取り込めないので、ちゃんとメールにデータを入力したものを添付して送ろうと言われるのはそのためです。
今回試したこと
今回試してみたのは出金伝票のフォーマットをExcelで作成し、そこにランダムなダミーデータを入力したものを10枚用意してみました。
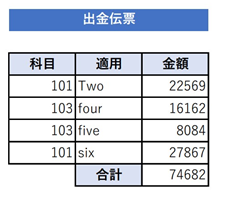
それを次々と読み出しExcelに入力してみました。
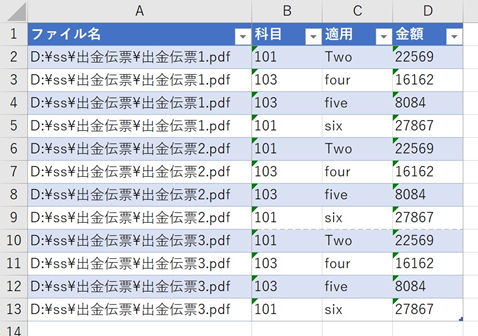
OCRでの取り込みの結果
1枚目は次のように取り込まれました。
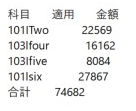
2枚目は次のように取り込まれました。

このように全く同じフォーマットにもかかわらず、一方はちゃんとした表形式で取り込まれているのに対して、項目名とデータの間に空白行がたくさん入ったり、項目名が1項目目しか入らなかったりといった違いがでてしまいました。
このような違いは何度もOCRに経験させてAIによって自動的に修正していけるような仕組みがあるRPAもあるのですが、Power Automate Desktopに今のところ確認できていないので、その仕組みはないと思われます。
このような違いが出てしまうのはなぜかを追求してもいいのですが、それは大変コストがかかることかもしれません。なによりもOCRがブラックボックスである以上それ以上の原因究明が我々にできるか考えるとできないような気がします。
そこで、このような違いを吸収する仕組みを我々が作らなければいけません。
そのために必要なのがどんなパターンがあってどのように対処すればできるのかを考える力です。
今回の対処法
今回のパターンは10枚の出金伝票をOCRで取り込んでみましたが上記の2パターンだけがありありました。まずこのように大雑把に分けて何パターンに分かれるのかを振り分けます。
そして全部のパターンに共通する修正する
科目という文字は必ず入るようなので、その行の次に空白行ではない行を見つけ、そこからの4行をデータとして取り込むことにします。
101とTwoの間の罫線を罫線として認識せず「|」として誤認識しています。しかも行によっては「|」や「¦」のような縦線に見えるものに認識していました。そこでこの罫線を誤認識した縦線をすべてピックアップしたところこの3種類だけだったので、それを列の分割の境界とすることにしました。また、Twoから次の数字までの間も数が決まっていない空白が入るので、これも対処しなければいけませんでした。
- 科目の文字の前に入っているものは捨てる
- 科目の文字 が入っていたら取り込み段階1へ
- 行全体を見て空白行でなければ取り込み段階2へ
- 取り込み段階2ならその行を取り込んで縦棒の種類をすべて「,」に変換
- 縦棒を「,」に変換したものの空白を1つにまとめすべて「,」に変換
- 空白を「,」に変換したものの「,」で列の境界にする
- ここまでを4行分実行し出来上がったデータを蓄積
以上の処理が必要になります。
具体的にはPower Automate Desktopでその対象をするよりも、ExcelのVBAを使って変換してしまった方が早かったので、Power Automate Desktopには、取り込んだ文字を決まったセルに入れ、処理用のExcelマクロを実行するだけとしました。
まとめ
どんなに優れたAIを使ったとしても完璧に認識できる自動化は永遠にできないのではないかと思っています。そこである程度、出来上がったものに対してパターン化してそのどのパターンだったらどんな対処をするか、それをできるだけ多いパターンで共通で使用できる対処法を考えるのが必要なのです。
自動化をすることはPower Automate Desktopの登場でハードルが下がってはいますが、望んでいる自動化のレベルによってはこのような対処法を考えていかないと自動化できないということになります。

コメント